Data from the Statistical "Which Character" Personality Quiz
The Statistical "Which Character" Personality Quiz has been overbuilt beyond the functionality of the quiz, for the purpose of making an interesting and bespoke dataset. It is hoped that this dataset can be useful for teaching statistics and data science with a topic that students should should already be familiar with and find interesting: fictional characters.
The dataset is based around 2,125 objects (fictional characters) and 500 features (bipolar adjective pairs). Since 2019, millions of people have rated the fictional characters, themselves, their relationship to the characters, and the relationships between characters in a number of different formats across a number of different surveys.
All of these datasets were collected with the same workflow. Users would take the personality quiz and at the end they are asked if they would be willing to answer a research survey before they view their results (about 40% do). You should take the quiz yourself to get a good grasp of how this works.
Datasets (downloadable)
There are several different datasets, each corresponding to a different supplemental survey. Each dataset includes the user's self reports from the quiz (somewhat degraded for user protection), their responses to the supplemental survey, and then a few demographic questions that are more or less standard across surveys, plus technical information about how that user interacted with the survey. Each dataset has a detailed coodbook, here is a general overview of the premise of each survey:
- SWCPQ-Features-Aggregated-Dataset (n=2,125 characters; 4MB). Data from the SWCPQ-Features-Survey-Dataset aggregated into character profiles.
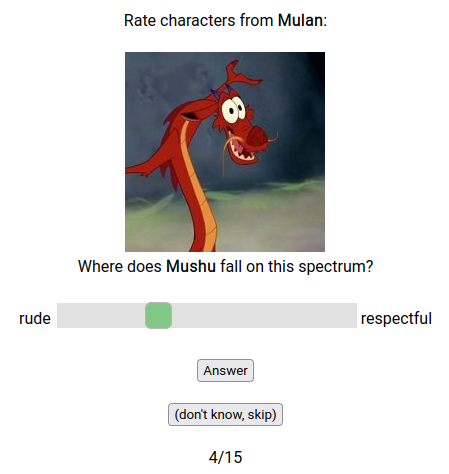
- SWCPQ-Features-Survey-Dataset (n=3,386,031; 1,165MB). The main survey, where users rate characters on different descriptions. e.g.
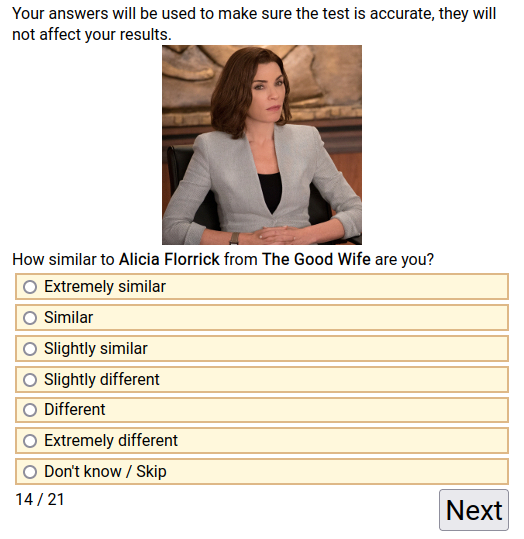
- SWCPQ-Identification-Survey-Dataset (n=297,877; 223MB). Users rate characters by how much they identify with them (how similar). See the below screenshot. Users who selected longer versions of the test (up to 245 items) were preferentially assigned to take this survey. So this is the dataset most useful for people interested in analyzing the the self-reports.
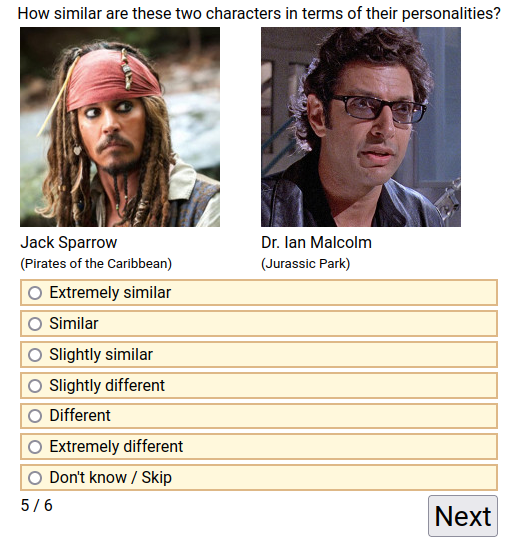
- SWCPQ-Similarity-Survey-Dataset (n=100,289; 73MB). Users rate pairs of characters on how similar they are. e.g.
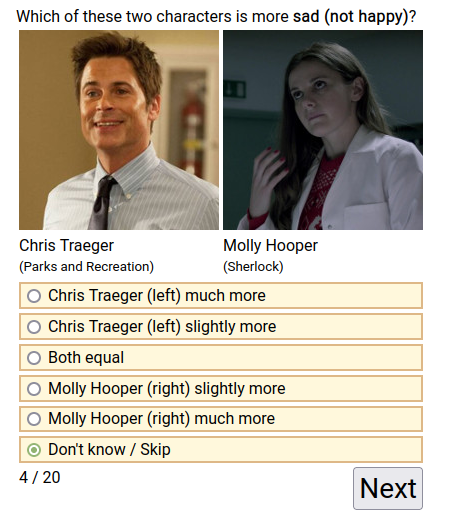
- SWCPQ-Ranking-Survey-Dataset (n=147,555; 100.2MB). Users rank two characters on the descriptive items. e.g.
Educational use cases
- Dimension Reduction: The dataset has 400 descriptions that were rated for each character, but probably a smaller set could convey most of the same informaion.
- Clustering: Are there types of characters?
- Interrater reliability: Which items have the greatest reliability? Do some characters evoke more consistent ratings across all items?
- Measurement invariance: Do the responses to the items mean the same things for different groups of characters? (hint: compare how rated height and actor height correlate and interact with sex of character)
- Collaborative filtering: Predict user identification with a character given their previous identifications.
- Machine learning: Predict user how similar two characters will be rated given their descriptive profiles.
- Critically evaluating pop-psych "personality types"